
Process Mining Engine
Summary
The Process Mining Engine is a composite component in the BPaaS Evaluation Environment which is responsible for executing process mining algorithms over the execution history of a BPaaS stored in the Semantic KB. This component is invoked by the Hybrid Dashboard to execute this required type of BPaaS analysis and visualise the respective analysis results according to the best possible visualisation metaphor.
While various kinds of process mining algorithms exist, we have selected to re-use only one kind for the moment. This kind maps to the recreation of a process model from the process log. This kind is quite useful for the optimisation of the BPaaS modelling as it enables to check which paths in the BPaaS workflow model are frequently executed, which are scarcely executed and which are not at all. As such, this can signify an indication to the modeller that possibly the paths that are never followed do not need to be modelled anymore. Concerning the other kinds of process mining algorithms that we intended to support, which include decision and organisational mining, they were not integrated for some technical reasons mapping mainly to the lack of some required data that could be collected from particular information sources in the CloudSocket platform (see D3.6 for more details). On the other hand, we do support semantic process mining as we can exploit semantic annotations over tasks in order to improve the accuracy of the process mining algorithms currently exploited.
The process model re-creation algorithms that we exploit come from the ProM process mining framework and constitute state-of-the-art algorithms. They are exploited as they are by appropriately creating a log from the Semantic KB mapping to the execution history of a certain BPaaS (either solely coupled to a specific customer or across all customers of that BPaaS) and then passing that log as input to these algorithms. This log conforms to the XES standard. Depending on the broker choice, this log can be formed by including either the names of the BPaaS workflow tasks in the log entries or the names of the concepts which have been used to annotate these workflow tasks. Upon successful execution, the result of each algorithm is then transformed again by exploiting the facilities of the ProM framework into a file conforming to BPMN which is the de facto standard adopted by CloudSocket.
As enabled as a feature by the Harvesting Engine, the Process Mining Engine does support multi-tenancy as it allows each broker to focus the analysis only on its own fragment in the Semantic KB. The whole process mining functionality is encapsulated for that reason in the form of a REST API which does take as input the id of the broker for which the analysis has to be performed. Apart from the core process mining functionality, this REST API offers a utility function that lists all state-of-the-art process mining algorithms that can be exploited by the broker. In this sense, via the interaction with the Hybrid Business Dashboard, the broker is listed with all these algorithms, he/she can select the one that is desired by him/her and then initiate its execution.
The Process Mining Engine can be easily replaced by another component developed externally by an organisation outside the CloudSocket consortium. This is due to the fact that this component is not tightly coupled with any other internal component in the BPaaS Evaluation Environment. It just communicates with the Semantic KB in order to retrieve the execution history of a certain BPaaS and exposes an API to the Hybrid Business Dashboard in order to enable its functionality to be invoked. In this sense, any replacement component would just have to conform to that API as well as be able to draw the correct information from the content of the Semantic KB.
The following table indicates the details of the component.
| Type of ownership | Creation |
| Original tool | ProM Process Mining Framework |
| Planned OS license | Mozilla Public Licence 2.0. |
| Reference community | ADOxx Community. |
Consist of
- Process Mining Service (REST API exposing the core functionality of this engine)
Depends on
- Semantic KB
Component responsible
| Developer | Company | |
|---|---|---|
| Kyriakos Kritikos | kritikos@ics.forth.gr | FORTH |
Architecture Design
The Process Mining Engine is is coloured in blue in the overall BPaaS Evaluation Environment architecture depicted in the figure below. As it can be seen, it is invoked by the Business Management Tool in order to invoke the right state-of-the-art process mining algorithm. This invocation, in turn, leads to exploiting the content of the Semantic KB at the Data Layer in order to support the creation of the log to be mined.
The final, internal architecture of the Process Mining Engine, which is depicted below, comprises the following 5 main components:
- Process Mining Service: A REST service which encapsulates the whole functionality of the Process Mining Engine in the form of REST API methods. Each method invoked triggers the execution of the Process Mining Orchestrator.
- Process Mining Orchestrator takes care of orchestrating the execution of the rest of the components in the architecture in order to support the satisfaction of the process mining request. For each process mining request, this component first invokes the Query Creator to create a SPARQL query which is then issued over the Semantic KB. The query result is then used to invoke the Log Creator in order to produce the required log which is exploited to execute the process mining algorithm selected from the Process Mining Library. The mining result is then transformed into BPMN form by exploiting a certain transformation algorithm from the Process Mining Library depending on the original form of the output supported by the executed process mining algorithm.
- Query Creator: this component, depending on the broker input which designates the BPaaS to be mined and optionally: (a) the customer to which the analysis should be restrained, (b) the period of the execution history and (c) whether semantic mining is to be performed, dynamically creates the right SPARQL query which can be issued over the Semantic KB in order to accurately obtain the right process log-oriented information to be used for the mining.
- Log Creator: this component takes the result of the SPARQL query execution and creates a log out of it which conforms to the XES standard. Depending on whether normal or semantic process mining needs to be supported, either the BPaaS workflow task names or their annotations are used to populate each entry of the log.
- Process Mining Library: this library has been constructed by exploiting some state-of-the-art process mining algorithms from ProM as well as the needed transformation algorithms (e.g., from petri net to BPMN) from the same framework that guarantee the final production of a BPMN recreated process model.
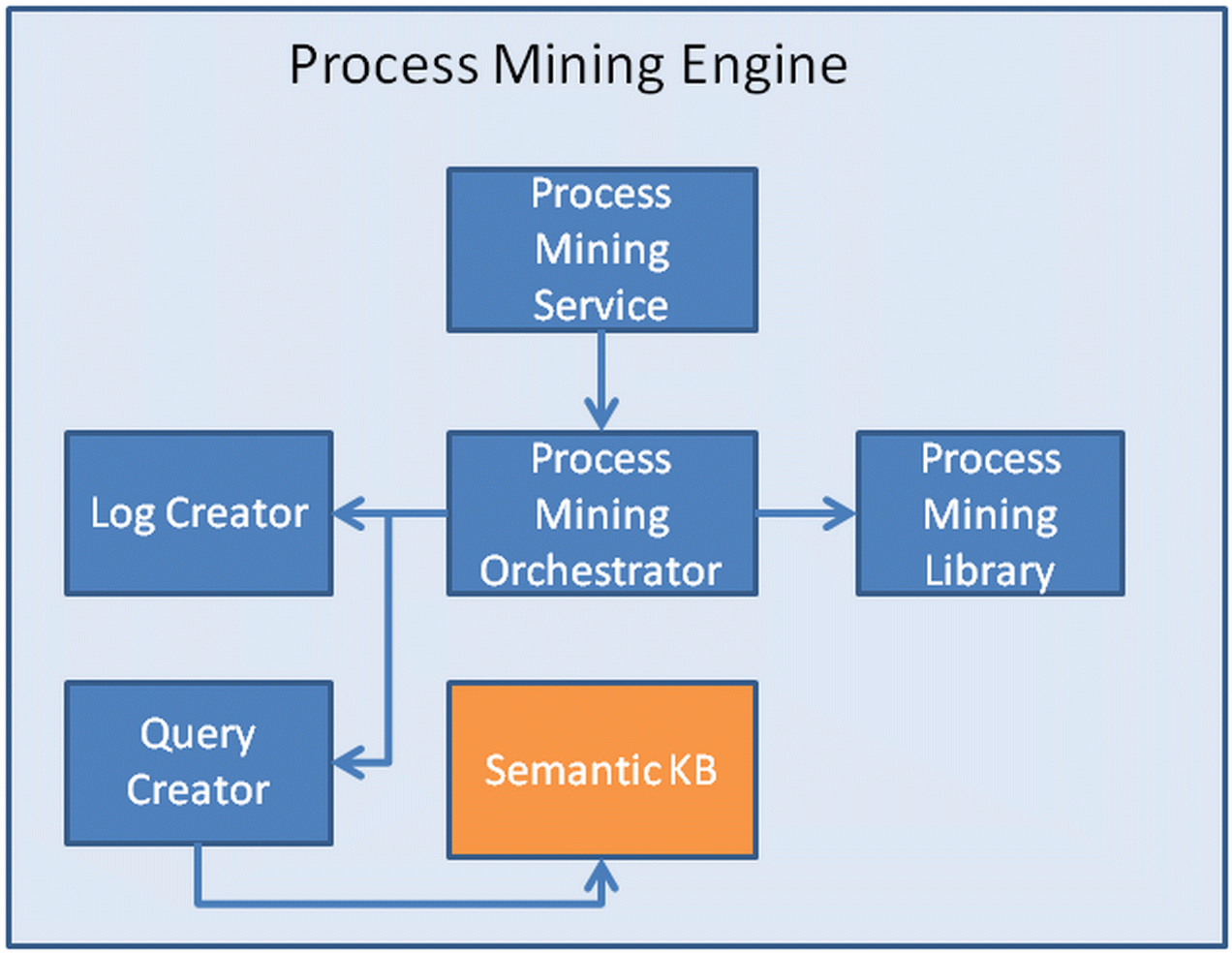 Architecture of the Process Mining Engine. |
Installation Manual
The component has been implemented purely in java. It depends on other external components / frameworks like ProM, OpenXES, Spring, swagger, jersey and sesame/open rdf. The following figure explicates the sole artefact generated mapping to this component as well as its dependencies on other artefacts (at a coarse-grained level to simplify the figure).
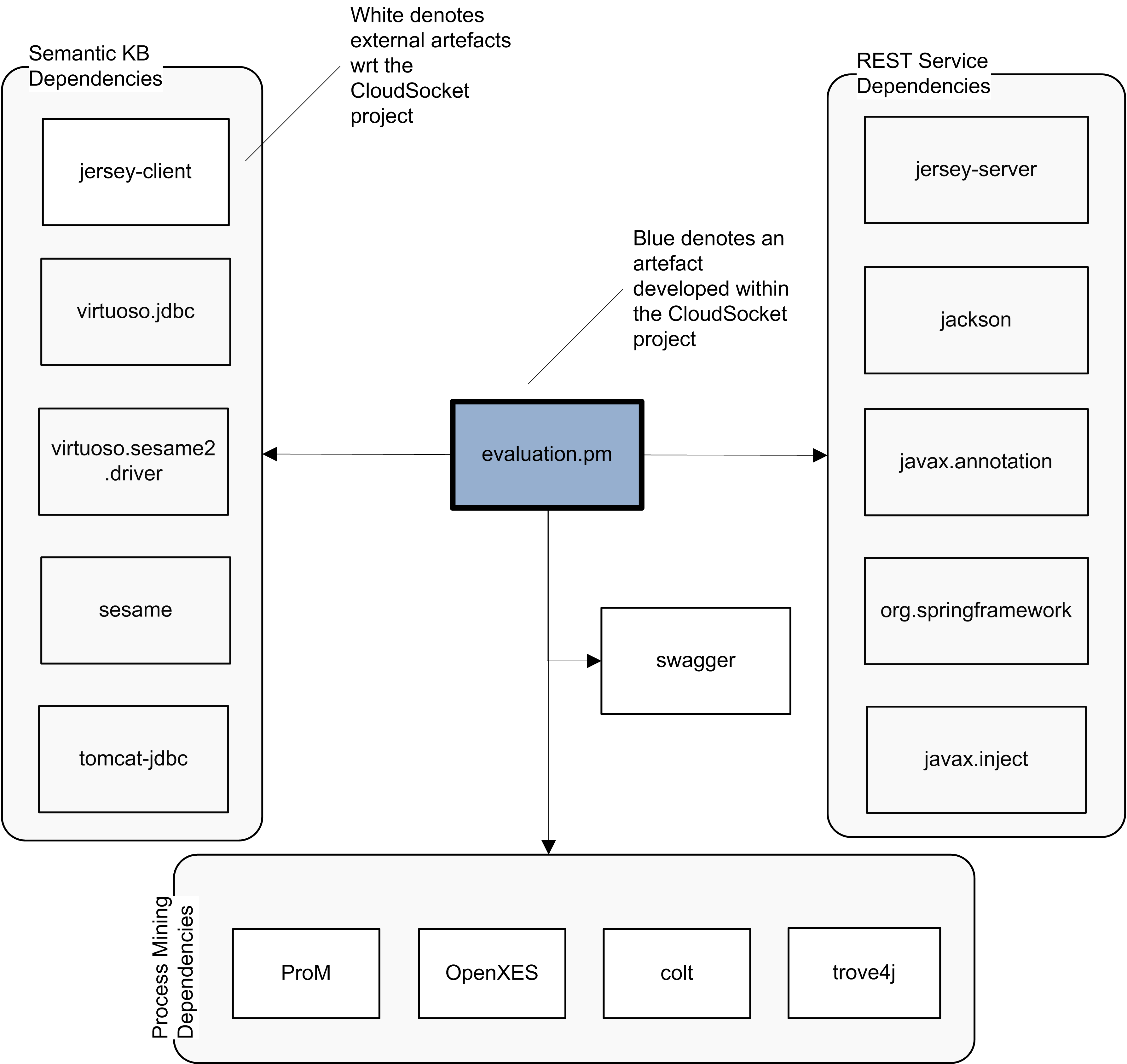 Artifact dependencies for the Process Mining Engine. |
Maven has been exploited as the main build automation tool, prescribing how the component/artefact can be built and its main dependencies. Such a tool facilitates the building and automatic generation of this artefact for the different CloudSocket environments (development and production) and their configuration. A complete description of how such artefact building and generation can be performed for the different environments is given in the installation manual below.
Development
Currently, the following requirements hold for this component:
- Oracle's 1.7.x JDK or higher
- Apache tomcat 1.7 or higher
- Maven tool for code compilation and packaging
The installation procedure to be followed is the one given below:
- Download source code from https://omi-gitlab.e-technik.uni-ulm.de/cloudsocket/evaluation_pm/repository/archive.tar?ref=master
- Unzip code with tar (or any other tool)
- Go to the root directory of the installed code
- Change the configuration file to provide the right access information for the Virtuoso Triple Store (https://virtuoso.openlinksw.com/)
- Run:
mvn clean install
and then:mvn war:war
- Move the war file to the webapps directory of tomcat and start tomcat, if not yet started
- Test installation by entering in your browser the following URL: http://localhost:8080/evaluation-pm/
Production
The same instructions as above hold for this component
Test Cases
You can run test cases directly from the URL (http://localhost:8080/evaluation-pm in your development environment) of the REST service due to the use of swagger (http://swagger.io) which enables the execution of the API method exposed by exploiting user input provided in a form-based manner. The following test cases are envisioned:
- Obtain all state-of-the-art process mining algorithms supported
At first contact, a broker might desire to see which process mining algorithms can be exploited. Moreover, this can be a first type of basic testing that the service is not only up but is also running correctly. To this end, the broker will go to the endpoint URL of the Process Mining Service and will click to expand the pmAlgorithms method. Then he/she can just press the "Try it out!" button to see the corresponding result. The following screenshot shows both the swagger-based description of this API method and the corresponding result of its invocation.
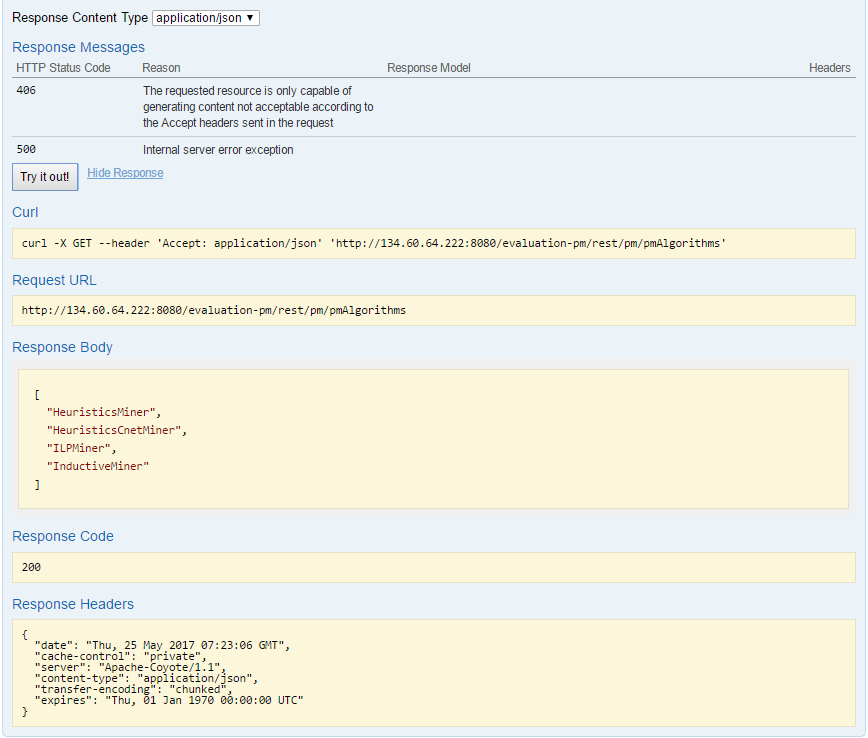 Result of executing the pmAlgorithms method of the Process Mining Service. |
- Run a process mining algorithm
This test case attempts to assess whether the core functionality of the Process Mining Engine is correctly delivered. In this respect, the broker should guarantee that the execution history of the BPaS to be examined already exists and has been stored in the Semantic KB. Once this check is done, then the respective testing of the mining functionality can proceed according to the following user story (where the id of the BPaaS can be of course interchanged with the one for which the execution history does exist).
Suppose that the user desires to mine the execution history of the "SendInvoiceSaaSEurope" BPaaS. Then, he/she can browse the methods of the API and click on the one named as "mine". The following screenshot indicates the upper part of the description of the method when selected:
 Swagger overview of the mine method of the Process Mining Service. |
Next, he/she can fill in the required input parameters, i.e., the name of the broker ("bwcon"), the id of the BPaaS bundle ("SendInvoiceSaaSEurope"). As he/she does not need to restrain the mining over one tenant as well as requires the whole execution history to be considered, the rest of the parameters are not touched. One this is done, then he/she can press the "Try it out!" button.
Finally, he/she will be able to see the respective curl command issued, the request URL, the corresponding results, as well as the response status and headers as indicated in the following figure:
 Result of calling the mine method of the Process Mining Service. |
User Manual
API Specification
The reader should refer to the Swagger-based API web page (http://localhost:8080/evaluation-pm for a local installation or http://134.60.64.222:8080/evaluation-pm for an existing remote installation) for browsing the API on-line documentation with the capability to execute the API methods. In the following, the API methods of the Process Mining Service are analysed below:
pmAlgorithms
This method enables to obtain the list of the state-of-the-art process mining algoriths that can be executed by the Process Mining Service. No input is required for executing this method.
POST pm/pmAlgorithms
The following response codes can be returned depending on whether the API method execution was successful or not:
- 200 -- The method execution was successful
- 406 -- The format requested for the method output is not supported
- 500 -- An internal server error has been generated
The output can be in both json and xml formats. A sample for a json output is given below:
[ "HeuristicsMiner", "HeuristicsCnetMiner", "ILPMiner", "InductiveMiner" ]
mine
This method enables to execute a certain state-of-the-art process mining algorithm (from those supported -- see previous method) over the execution history of a specific BPaaS:
POST pm/mine/{brokerId}
The expected input format is multipart/form-data. The following input parameters are expected:
- brokerId: denotes the id of the broker for which the mining needs to be performed. It is a path parameter as it can be seen from the method relative URL (obligatory)
- bundleId: denotes the id of the BPaaS bundle for which the mining needs to be performed (obligatory)
- minePeriod: denotes the extent of the execution history from the current moment in the form of a Java period (a possible value, e.g., "P1M" would then declare a period of 1 month until now) (optional)
- tenant: denotes the id of the tenant/customer for which the mining can be performed. This will restrict the execution history to include only information pertaining to the instance(s) of the BPaaS at hand that have been purchased by this tenant (optional)
- algorithm: denotes the name of the state-of-the-art algorithm to be used for the process mining. This name can be obtained by calling the previous method ("pmAlgorithms") (obligatory)
- semantic: denotes whether semantic or normal process mining must be performed. The default value is false (favouring normal process mining) (obligatory)
The following response codes can be returned depending on whether the API method execution was successful or not:
- 200 -- The method execution was successful
- 400 -- Wrong parameter values have been provided
- 404 -- The resource requested (i.e., the broker) was not found
- 406 -- The format requested for the method output is not supported
The output will be strictly for now in BPMN form. A sample of such an output is given below:
<b> to include the description of the BPMN process model here </b>
Handbook
Funding Partners

Horizon 2020