
Harvesting Engine
Summary
The Harvesting Engine is a composite component in the BPaaS Evaluation Environment which is dedicated to:(a) the collection of deployment, monitoring and registry information from the BPaaS Execution Environment and the Repository Manager; (b) the semantic transformation and linking of that information; (c) the storage of that information in the Semantic KB.
While this component is independent of the analysis components in the BPaaS Evaluation Environment, it actually enables them as it provides the proper information via which the corresponding analysis can be performed. To this end, by also considering that the information to be collected does not need to be harvested very frequently in order not to overwhelm the environment, this component is run periodically in order to perform its harvesting, semantic linking and storage job in the form of a Java thread.
The Harvesting Engine is the component which also enables multi-tenancy in the BPaaS Evaluation Environment. As the sole user of that environment is the CloudSocket broker, multi-tenancy is offered in the form of the capability to simultaneously handle multiple brokers. This is achieved by the careful storage of the harvested information into disjoint, broker-specific fragments in the Semantic KB that only the corresponding broker can see and reason about. To this end, by knowing exactly which broker makes the respective analysis request, the corresponding analysis components in the BPaaS Evaluation Environment can focus their analysis only on the fragment attributed to the broker concerned.
The information harvesting is performed by invoking the REST APIs offered by corresponding components in the CloudSocket platform. As such, the information sources currently exploited span: (a) the Workflow Engine (for collecting workflow modelling, task-to-service deployment & instance-based information); (b) the Cloud Provider Engine (for collecting service-to-IaaS deployment & monitoring definition information); (c) the Monitoring Engine (for collecting produced monitoring information); (d) the Repository Manager (for collecting information from the Abstract Service, Concrete Service and Software Component Registries).
The collected information is semantically transformed and linked by conforming to the Evaluation and OWL-Q (KPI Extension) ontologies. This means that the information is triplified according to the schema of these ontologies by also handling the corresponding links between the rdf resources generated for cross-points between the two ontologies. Such linking enables to connect deployment and monitoring information in order to allow the posing of suitable KPI metric evaluation queries which aggregates measurements only for those BPaaS elements that are correlated with a certain deployment hierarchy.
This component is not easily replaceable as it is the glue point between BPaaS evaluation-related and many other CloudSocket components in other environments. As such, the internal logic of that component could be quite hard to reproduce unless there is a deep knowledge of all the components from which this component has to extract information. In addition, there is the need to possess a good level of expertise in semantic technologies to realise this component due to the requirement to structure and link the harvested information based on the two ontologies considered.
The following table indicates the details of the component.
| Type of ownership | Creation |
| Original tool | New component developed in the context of this project |
| Planned OS license | Mozilla Public Licence 2.0. |
| Reference community | ADOxx Community. |
Consist of
- Harvester (main orchestration component run in the form of a Java thread)
Depends on
- Semantic KB
- Workflow Engine
- Cloud Provider Engine
- Monitoring Engine
- Repository Manager (only the aforementioned registries which are directly accessed via their REST API)
Component responsible
| Developer | Company | |
|---|---|---|
| Kyriakos Kritikos | kritikos@ics.forth.gr | FORTH |
Architecture Design
The Harvesting Engine is coloured in purple in the overall BPaaS Evaluation Environment architecture depicted in the figure below. As it has been already stated, this is an independent component (inside the BPaaS Evaluation Environment) which only communicates with the Semantic KB in order to store the information collected and semantically lifted.
The final, internal architecture of the Harvesting Engine, which is depicted below, comprises 9 main components:
- Harvester: This is the main component that coordinates the harvesting of the information to be collected from the BPaaS Execution Environment and the Repository Manager. Such a harvesting follows a 3 step process: (a) first IaaS service & cloud information is collected from the Cloud Provider Engine; (b) then workflow, deployment and monitoring definition information is collected from the Workflow Engine and the Cloud Provider Engine; (c) finally, monitoring information is collected from the Monitoring Engine. The component also takes care of how to enforce multitenancy by appropriately managing the broker-specific fragments and populating them with either general, cross-broker information or information that pertains only to the broker concerned.
- 5 components are extraction components which collect information from different CloudSocket components by calling their REST APIs. These components include: (a) the Deployment Extractor (deployment information collection); (b) the WF Engine Extractor (workflow-related information extraction); (c) Registry Extractor (registry information collection); (d) Monitoring Extractor (monitoring information extraction); (e) Marketplace Extractor (marketplace information collection -- not yet implemented).
- BPMN Parser: takes care of parsing the BPMN model of the BPaaS workflow that has been collected from the WF Engine Extractor and of enforcing the triplification of the workflow-related information
- CAMEL Parser: this component extracts the CAMEL model of the BPaaS workflow in order to obtain component and component-to-VM/IaaS deployment information as well as is capable of transforming the monitoring and KPI definition part of CAMEL into an OWL-Q model which is stored in the Semantic KB.
- Triple Importer: this is the component which takes care of the triplification of the collected information, its semantic linking based on the schema of the two ontologies and the storage of this information in the Semantic KB
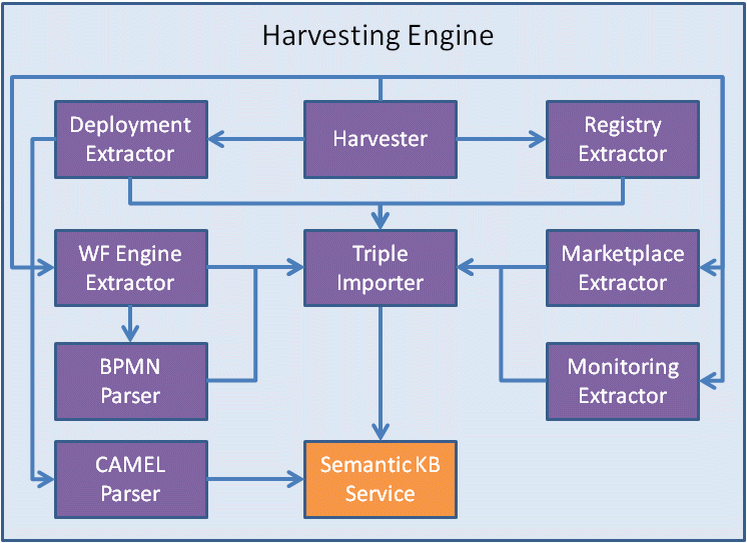 Architecture of the Harvesting Engine. |
Installation Manual
The component has been implemented purely in java. It depends on other external components / frameworks like jersey (for making REST requests to the CloudSocket APIs) and sesame/rdf4j (for the semantic storage of the triplified information in the Semantic KB. It also depends on an internal component developed in the context of this project, the owl-q one which enables the parsing of OWL-Q models into domain-specific objects as well as their writing. The following figure explicates the sole artefact generated mapping to this component as well as its dependencies on other artefacts (at a coarse-grained level to simplify the figure).
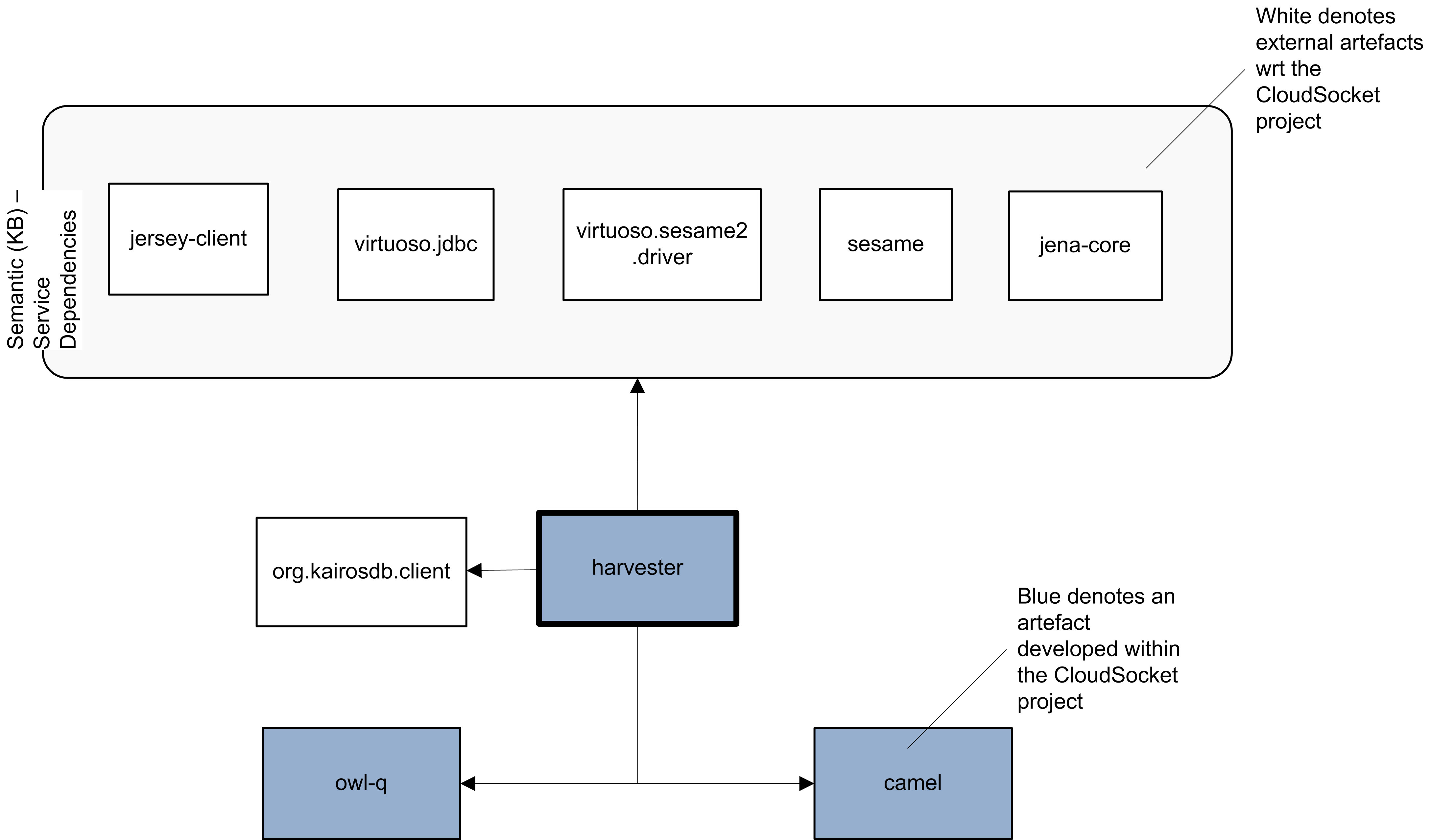 Artifact dependencies for the Harvesting Engine. |
Maven has been exploited as the main build automation tool, prescribing how the component/artefact can be built and its main dependencies. Such a tool facilitates the building and automatic generation of this artefact for the different CloudSocket environments (development and production) and their configuration. A complete description of how such artefact building and generation can be performed for the different environments is given in the installation manual below.
Development
Currently, the following requirements hold for this component:
- Oracle's 1.7.x JDK or higher
- Maven tool for code compilation and packaging
The installation procedure to be followed is the one given below:
- Download source code from https://omi-gitlab.e-technik.uni-ulm.de/cloudsocket/harvester/repository/archive.tar?ref=master
- Unzip code with tar (or any other tool)
- Go to the root directory of the installed code
- Change the configuration file to provide the right connection information to all the information sources exploited
- Run:
mvn clean install
to compile the source code - Run:
mvn exec:java -Deu.cloudsocket.configdir=.
to run the component as a Java thread which is configured by reading the "eu.cloudsocket.evaluation.dd.properties" configuration file from the current directory - As the component runs in command line mode, it is easy to check whether the component is running normally. In case that you need to examine the content that it generates, you should connect to the Triple Store of the Semantic KB and pose some SPARQL queries to draw and inspect it. This can be more easily done when the Triple Store is immediately empty.
Production
The same instructions as above hold for this component
Test Cases
As this component runs as a Java thread, it can be immediately inspected if it exhibits any bug (by, e.g., taking care of creating a log out of the printed output). In order to check also the content that it generates, a set of SPARQL queries can be posed over the Triple Store of the Semantic KB. If this triple store is developed locally, then you can connect to the local Virtuoso (Triple) Server endpoint (at http://localhost:8890/sparql) and then pose the queries from there, especially as it exhibits a nice interface to run SPARQL queries and visualise their results. If you desire to exhibit an existing endpoint, you can direct your queries at: http://134.60.64.222:8890/sparql.
The SPARQL queries, which act as test cases that can be posed and inspected if they produce a respective result, involve the following:
- Get all BPaaS workflow tasks and their input and output parameters -- this query tests whether we can obtain correctly workflow information from the Workflow Engine and to correctly correlated it
PREFIX eval: <http://www.cloudsocket.eu/evaluation#> SELECT ?name ?id1 ?id2 from <http://www.cloudsocket.eu/evaluation/bwcon> WHERE { ?t eval:name ?name. { ?t a eval:ServiceTask } UNION { ?t a eval:ScriptTask } UNION {?t a eval:UserTask} optional{ ?t eval:inputVariable ?v1. ?v1 eval:id ?id1. } optional{ ?t eval:outputVariable ?v2. ?v2 eval:id ?id2. } } - Get user id as well as information about the roles assigned to the user (id, name and type) for the customers over all BPaaSes -- this query tests the ability of the Harvesting Engine to collect customer-specific information in the context of a BPaaS (workflow). The users collected map to the customer organisation but the roles are defined in the context of BPaaS workflow execution and not in general for the organisation. This means that Knowledge Worker can be a generic organisation role which would characterise a user responsible for the execution of user tasks in corresponding BPaaS workflow instances that is not currently captured but "accounting" can be a captured role which maps to a specific fragment of a BPaaS workflow denoting a person responsible for accounting-related tasks.
PREFIX eval: <http://www.cloudsocket.eu/evaluation#> SELECT ?name ?rid ?rname ?rtype from <http://www.cloudsocket.eu/evaluation/bwcon> WHERE { ?u a eval:User; eval:name ?name; eval:role ?r1. ?r1 eval:id ?rid; eval:name ?rname; eval:type ?rtype. } - Get allocation information for each BPaaS which includes the workflow allocated, the allocation itself, the allocated task, the name of the (external or internal) SaaS service realising the functionality of the task, and the name of the IaaS service on which an internal SaaS service is deployed -- this information enables to check whether information from the Workflow Engine and the registries of the Repository Manager can be appropriately harvested and correctly correlated.
PREFIX eval: <http://www.cloudsocket.eu/evaluation#> SELECT ?bpaasId ?workflow ?alloc ?taskName ?serviceName ?iaasName from <http://www.cloudsocket.eu/evaluation/bwcon> WHERE { ?bpaas eval:allocation ?alloc; eval:id ?bpaasId; eval:workflow ?workflow. ?alloc eval:allocatedTask ?task; eval:selectedService ?service. ?task eval:name ?taskName. ?service eval:name ?serviceName. optional{ ?alloc eval:selectedIaaS ?iaas. ?iaas eval:name ?iaasName. } } - Get information about all IaaS services -- this query tests whether we can obtain IaaS-related information from the Cloud Provider Engine
PREFIX eval: <http://www.cloudsocket.eu/evaluation#> SELECT ?iaas ?name ?coreNumber ?memorySize ?storageSize from <http://www.cloudsocket.eu/evaluation/bwcon> WHERE { ?iaas a eval:IaaS; eval:name ?name; eval:coreNumber ?coreNumber; eval:memorySize ?memorySize; eval:storageSize ?storageSize. } - Get information about all SaaS services -- This query tests whether we can successfully obtain and correlate SaaS-related information from the (Abstract/Concrete) Service and Software Component Registries of the Repository Manager
PREFIX eval: <http://www.cloudsocket.eu/evaluation#> SELECT ?service ?serviceName ?serviceOid ?serviceEndpoint from <http://www.cloudsocket.eu/evaluation/bwcon> WHERE { ?service rdf:type ?type; eval:name ?serviceName; eval:registryId ?serviceOid; eval:endpoint ?serviceEndpoint. FILTER(?type IN (eval:ExternalSaaS, eval:ServiceComponent)) } - Get information about the instances of a deployed workflow and its tasks -- This query tests whether we can retrieve instance-based information from the Workflow Engine and correctly link it to the deployed workflows and tasks already modelled.
PREFIX eval: <http://www.cloudsocket.eu/evaluation#> SELECT ?depWF ?depTask ?wfInstance ?taskInstance from <http://www.cloudsocket.eu/evaluation/bwcon> WHERE { ?depWF eval:workflowInstance ?wfInstance; eval:deployedTask ?depTask. ?depTask eval:taskInstance ?taskInstance. } - Get (not task-related) information about a workflow instance -- This query tests whether we can obtain workflow instance information from the Workflow Engine
PREFIX eval: <http://www.cloudsocket.eu/evaluation#> SELECT ?wfInstance ?startTime ?endTime ?endState ?initiator from <http://www.cloudsocket.eu/evaluation/bwcon> WHERE { ?wfInstance rdf:type eval:WorkflowInstance; eval:startTime ?startTime; eval:endTime ?endTime; eval:endState ?endState; eval:initiator ?initiator. }
User Manual
Handbook
Funding Partners

Horizon 2020