
Deployment Discovery Engine
Summary
The Deployment Discovery Engine is a composite component in the BPaaS Evaluation Environment which is responsible for discovering best deployments for a BPaaS according to the deployment and measurement history of this and other similar or equivalent BPaaS to this BPaaS, as being stored in the Semantic KB. This component is invoked by the Hybrid Dashboard to execute this required type of BPaaS analysis and visualise the respective analysis results according to the best possible visualisation metaphor.
The discovery of best deployments currently relies on three main factors:
- workflow equivalence/similarity: as an execution history of a BPaaS can be limited or non-existing as in the case of a new BPaaS, we need to find a way to explore the measurement and deployment history of other BPaaSes that are similar or equivalent to the current one. To this end, BPaaS similarity or equivalence needs to be formally defined and the means to achieve it realised. Our main way of addressing this was to rely on workflow similarity, i.e., compare the workflows of the BPaaSes concerned in order to infer their similarity. Workflow similarity, in turn, is mapped to task equivalence which is enforced by considering the task name. In other words, two workflows are equivalent if they include the same tasks -- we assume here that probably the structure of the workflow is similar although this might not be true in all possible cases. On the other hand, two workflows are similar if they share a certain percentage (75% currently but this can be configured) of equivalent tasks.
- evaluation of "best" deployment: by considering that each BPaaS might have its own KPIs that need to be respected, it can be impossible to use a certain set of KPIs that can be common among many BPaaSes to evaluate whether a certain deployment can be considered as "best" or not. In order to remedy for this, we attempt to abstract away from KPIs by considering the overall level of QoS which can be considered to be derived via a weighted sum approach over utility functions constructed for each specific KPI metric exploited. In this sense, via such a normalisation and aggregation, each deployment then maps to just one overall QoS value and then ranking can be performed to infer which deployment is the best.
- deployment selection: while it could be argued that each deployment of a BPaaS should be considered in the analysis, this can be quite risky as this might also map to taking into account deployments for which the KPIs have been violated. While this might not occur so frequently, it can still lead to economic loss for the broker and is thus subject for performing deployment filtering. This means that only deployments which have been successful in the past by not violating any KPI should be considered in the best deployment analysis. As such, the risk of violating a KPI would be the minimum possible while the probability of achieving a better or higher service level will be increased.
Based on the above analysis, there is no need for the user to provide a special input to this engine apart from providing the id of the BPaaS for which the analysis needs to be performed. In addition, the user can restrain the execution (measurement & deployment) history within a certain period with the rationale that possibly more recent periods might involve the execution of more optimised BPaaSes. The result of the best BPaaS deployment analysis takes the form of two tables which include: (a) the mapping of each service task to a certain SaaS (internal or external) and (b) the mapping of each internal SaaS to a certain IaaS. Currently, JSON is supported but in the future possibly DMN and/or CAMEL could also be included in the support list by also giving the user the opportunity to select the most appropriate form of the output (to check).
As enabled as a feature by the Harvesting Engine, the Deployment Discovery Engine does support multi-tenancy as it allows each broker to focus the analysis only on its own fragment in the Semantic KB. For this reason, the best deployment functionality is encapsulated in the form of a REST API with a single method which does take as input the id of the broker for which the analysis has to be performed plus optionally the history period for this analysis.
The Deployment Discovery Engine can be easily replaced by another component developed externally by an organisation outside the CloudSocket consortium. This is due to the fact that this component is not tightly coupled with any other internal component in the BPaaS Evaluation Environment. It just communicates with the Semantic KB in order to retrieve all the necessary information for inferring workflow equivalence and producing the rank of successful deployments, while it exposes an API to the Hybrid Business Dashboard in order to enable its functionality to be invoked. In this sense, any replacement component would just have to conform to that API as well as be able to draw the correct information from the content of the Semantic KB.
The following table indicates the details of the component.
| Type of ownership | Creation |
| Original tool | Drools Knowledge Base Framework |
| Planned OS license | Mozilla Public Licence 2.0. |
| Reference community | ADOxx Community. |
Consist of
- Deployment Discovery Service (REST API exposing the core functionality of this engine)
Depends on
- Semantic KB
Component responsible
| Developer | Company | |
|---|---|---|
| Kyriakos Kritikos | kritikos@ics.forth.gr | FORTH |
Architecture Design
The Process Mining Engine is is coloured in deep blue in the overall BPaaS Evaluation Environment architecture depicted in the figure below. As it can be seen, it is invoked by the Business Management Tool in order to start the best deployment analysis. This invocation, in turn, leads to exploiting the content of the Semantic KB at the Data Layer in order to retrieve the most suitable information needed to support this analysis.
The final, internal architecture of the Deployment Discovery Engine, which is depicted below, comprises the following 5 main components:
- Deployment Discovery Service: A REST service which encapsulates the functionality of the Deployment Discovery Engine in the form of a REST API method. Internally, this service triggers the execution of the Deployment Discovery Orchestrator upon each service request.
- Deployment Discovery Orchestrator: it takes care of orchestrating the execution of the rest of the components in the architecture in order to support the satisfaction of the best deployment discovery request. For each such request, this component invokes the Semantic Information Extractor to retrieve the most suitable information for the analysis from the Semantic KB which is then inserted in the form of facts inside the Knowledge Base. Then, the all rules of that Knowledge Base are fired which might invoke both the Semantic Information Extractor for the retrieval of additional information as well as the Smart Service Discovery & Selection Tool for inferring equivalence facts between different BPaaS elements.
- Semantic Information Extractor: this component is capable of forming SPARQL queries which are then issued over the Semantic KB. It is also capable of transforming the query results into domain objects that can then be inserted inside the Knowledge Base.
- Knowledge Base/KB: this component represents a normal knowledge base in which the rules for the best BPaaS deployment discovery are stored. This KB also enables the generation of sessions via which facts can be stored and rules can be fired to operate over these facts.
- Smart Service Discovery & Selection Tool: this component has been produced in the research WP of the CloudSocket project ( provide link to the innovation shop). It enables the semantic functional and non-functional discovery of various kinds of services as well as the global selection of services in the context of a specific BPaaS workflow. It is mainly used in the Deployment Discovery Engine in order to infer the equivalence between services ( check if this is true or it can be considered as a future feature to implement.
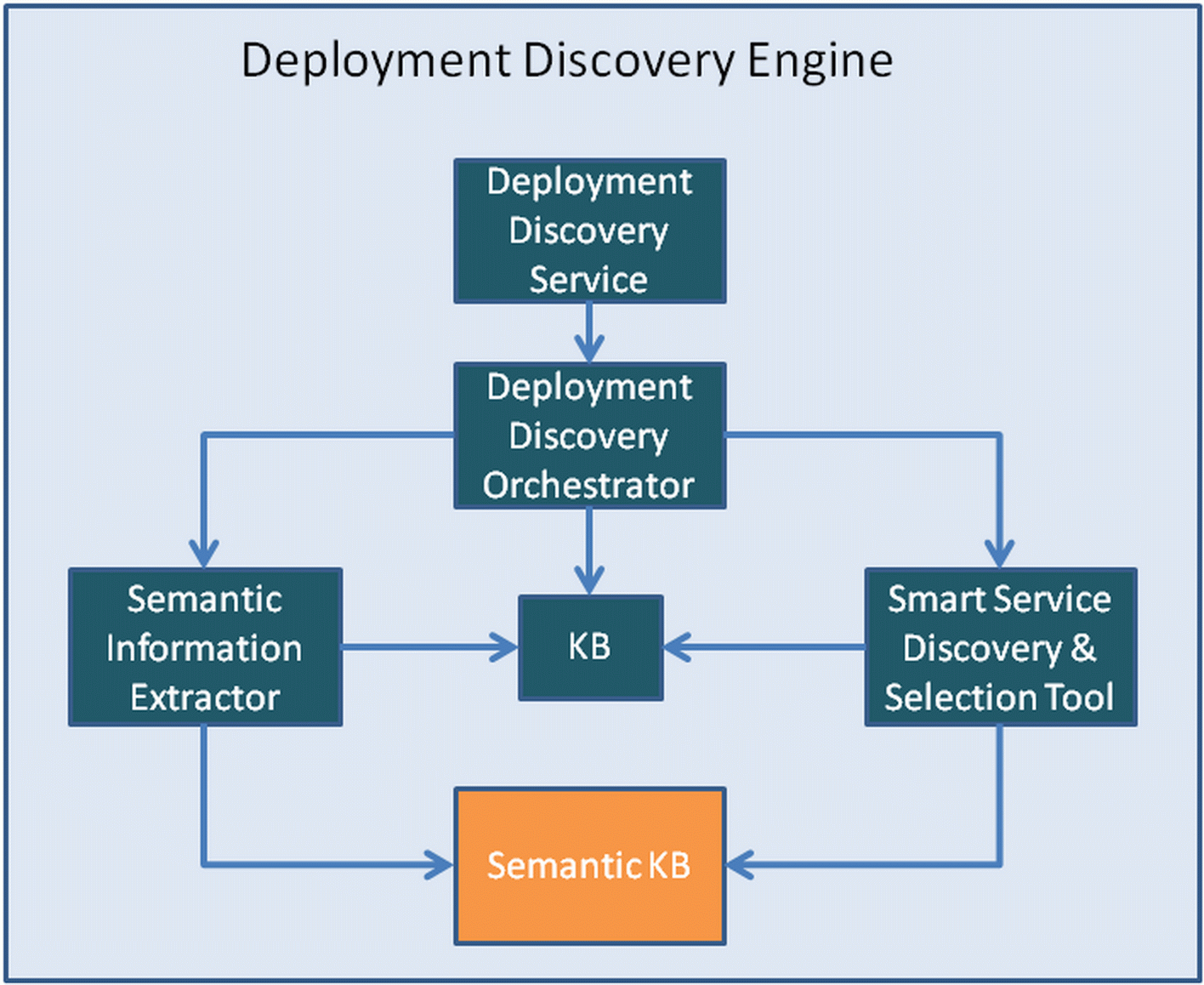 Architecture of the Deployment Discovery Engine. |
Installation Manual
The component has been implemented purely in java. It depends on other external components / frameworks like Spring, swagger, jersey and sesame/rdf4j. The following figure explicates the sole artefact generated mapping to this component as well as its dependencies on other artefacts (at a coarse-grained level to simplify the figure).
 Artifact dependencies for the Deployment Discovery Engine. |
Maven has been exploited as the main build automation tool, prescribing how the component/artefact can be built and its main dependencies. Such a tool facilitates the building and automatic generation of this artefact for the different CloudSocket environments (development and production) and their configuration. A complete description of how such artefact building and generation can be performed for the different environments is given in the installation manual below.
Development
Currently, the following requirements hold for this component:
- Oracle's 1.7.x JDK or higher
- Apache tomcat 1.7 or higher
- Maven tool for code compilation and packaging
The installation procedure to be followed is the one given below:
- Download source code from https://omi-gitlab.e-technik.uni-ulm.de/cloudsocket/evaluation_dd/repository/archive.tar?ref=master
- Unzip code with tar (or any other tool)
- Go to the root directory of the installed code
- Change the configuration file to provide the right access information for the Virtuoso Triple Store (https://virtuoso.openlinksw.com/)
- Run:
mvn clean install
and then:mvn war:war
- Move the war file to the webapps directory of tomcat and start tomcat, if not yet started
- Test installation by entering in your browser the following URL: http://localhost:8080/evaluation-dd/
Production
The same instructions as above hold for this component
Test Cases
You can run test cases directly from the URL (http://localhost:8080/evaluation-dd in your development environment) of the REST service due to the use of swagger (http://swagger.io) which enables the execution of the API method exposed by exploiting user input provided in a form-based manner. The following test cases are envisioned:
- Retrieve the best deployments for a BPaaS
This test case attempts to assess whether the core functionality of the Deployment Discovery Engine is correctly delivered. In this respect, the broker should guarantee that there exist deployments for the required BPaaS to be analysed or for BPaaSes that are similar or equivalent to it and have been coupled with monitoring information (which could be done by exploring the content of the Semantic KB). Once this check is done, then the respective testing of the best deployment discovery functionality can proceed according to the following user story (where the id of the BPaaS can be of course interchanged with the one for which the analysis can be really performed).
Suppose that the user desires to find the best deployments of the "SendInvoiceSaaSEurope" BPaaS. Then, he/she can browse the methods of the API and click on the one named as "deploymentDiscovery". The following screenshot indicates the upper part of the description of the method when selected:
 Swagger overview of the "deploymentDiscovery" method of the Deployment Discovery Service. |
Next, he/she can fill in the required input parameters, i.e., the name of the broker ("bwcon"), the id of the BPaaS bundle ("SendInvoiceSaaSEurope") and optionally the analysis period. As he/she does require the whole execution history to be considered, the input to the "analysisPeriod" parameter is not given. Once the filling of the parameters is completed, then he/she can press the "Try it out!" button.
Finally, he/she will be able to see the respective curl command issued, the request URL, the corresponding results, as well as the response status and headers as indicated in the following figure:
 Result of calling the deploymentDiscovery method of the Deployment Discovery Service. |
User Manual
API Specification
The reader should refer to the Swagger-based API web page (http://localhost:8080/evaluation-dd for a local installation or http://134.60.64.222:8080/evaluation-dd for an existing remote installation) for browsing the API on-line documentation with the capability to execute the API methods. In the following, the API methods of the Process Mining Service are analysed below:
deploymentDiscovery
This method enables to execute the best deployment discovery functionality and retrieve back the corresponding results:
POST dd/deploymentDiscovery/{brokerId}
The expected input format is multipart/form-data. The following input parameters are expected:
- brokerId: denotes the id of the broker for which the best deployment discovery needs to be performed. It is a path parameter as it can be seen from the method relative URL (obligatory)
- bundleId: denotes the id of the BPaaS bundle for which the analysis needs to be performed (obligatory)
- analysisPeriod: denotes the extent of the execution history from the current moment in the form of a Java period (a possible value, e.g., "P1M" would then declare a period of 1 month until now) (optional)
The following response codes can be returned depending on whether the API method execution was successful or not:
- 200 -- The method execution was successful
- 400 -- Wrong parameter values have been provided
- 404 -- The resource requested (i.e., the broker) was not found
- 406 -- The format requested for the method output is not supported
The output will be in either JSON or XML form for now. A sample of a JSON-based output is given below:
<b> to include the description of the result here </b>
Handbook
Funding Partners

Horizon 2020